[Seaborn 라이브러리]
- 다양한 통계 그래프 작성에 용이
- https://seaborn.pydata.org/examples/index.html
- 실습 데이터 세트 (seaborn에 있는 데이터 사용)
- flights: 월별 비행기 탑승객 수 데이터
- tips : 팁관련 데이터
- mpg: 자동차 연비관련 데이터
그래프의 종류 (Seaborn)
- 1.선그래프 (sns.lineplot)
- 2.막대그래프 (sns.barplot/sns.countplot)
- 3.산점도 (sns.scatterplot)
- 4.히스토그램 (sns.histplot, displot)
- 5.박스플롯 (sns.boxplot)
- 6.히트맵 (sns.heatmap)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings as wn
wn.filterwarnings('ignore') #(그래프의 오류를 일시적으로 가리는 코드)
sns.lineplot(x=x,y=y)
2)데이터프레임 그리기
# 데이터 로드
flights = sns.load_dataset("flights")
flights['month']=='May'
0 False
1 False
2 False
3 False
4 True
...
139 False
140 False
141 False
142 False
143 False
Name: month, Length: 144, dtype: bool
may_flights = flights[flights['month']=='May']
may_flights

sns.lineplot(x = may_flights['year'], y= may_flights['passengers'])
plt.show()

or
#data인수에 데이터프레임
# x와 y에 각각 x축에 사용할 열이름(year)과 y축에 사용할 열이름(passengers) 지정
sns.lineplot(data=may_flights, x="year", y="passengers")
plt.show()
2. 막대그래프
(1) barplot
sns.barplot(data=may_flights, x="year", y="passengers")

- 원래 특정변수의 평균값을 그려주다. bar plotting (하지만 위의 데이터는 값이 하나라서 평균값이 아니다)
- ex) 요일별 tip값의 평균을 보고 싶다면?
* tips 데이터 로딩
tips = sns.load_dataset("tips")
tips.head(30)
#요일별 tip값의 평균
sns.barplot(data=tips, x='day', y='tip')
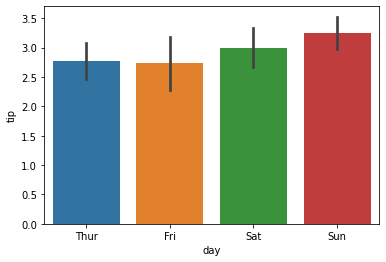
- 각 막대에 기본적으로 오차막대(error bar)가 함께 나타남
- 오차막대: 신뢰구간(confidence interval)
- 이 데이터를 기반으로 유사한 상황의 95 % 범위 내에서 결과를 얻을 것을 의미
- ci=None(오차막대 안그림)
- 요일별 성별 세분화 표시
- 구분자 hue 이용
sns.barplot(x="day", y="tip", hue="sex", data=tips, ci=None)
plt.show()

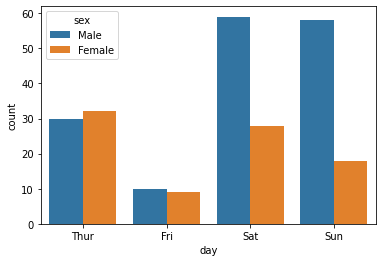
(2) countplot
* **데이터의 갯수를 count하여 barplotting**
# day별 tips의 총합
sns.countplot(x = "day", data = tips)
plt.show()
#y축을 설정할 필요가 없다(개수만 세면 되니깐)

sns.countplot(x = "day", data = tips, hue = "sex")
plt.show()
3. 산점도 - scatterplot
- 산점도 그리기
- x축 total_bill
- y축 tip
sns.scatterplot(data = tips, x = "total_bill", y = "tip")

4. 히스토그램/커널 밀도 그래프
histplot (히스토그램)
#! pip install seaborn
#! pip install matplotlib
#seaborn버전이 낮을 경우 histplot, displot이 되지 않음. 업그레이드 필요함
#업그레이드 후에는 커널을 다시 시작해야 함
# tips 데이터
tips
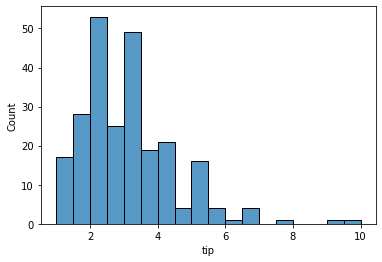
sns.histplot(data = tips, x = "tip") #sns.histplot(tips.tip)
plt.show()
displot
- kind 를 이용하여 다양한 함수를 그릴 수 있다.
- 예) histplot(hist), kdeplot(kde), ecdfplot(ecdf)
-kind 사용
- hisplot (hist)
- 히스토그램(histogram) 그래프를 그리는 함수로 데이터의 빈도
- count(절대량)을 표현
- kdeplot (kde)
- 커널 밀도 추정(kernal density estimation) 그래프
- 비율(상대량)을 시각화
- ecdfplot(edf)
- 분포 누적화
sns.displot(x='tip', data = tips)
sns.displot(x='tip', data = tips, kind = 'hist')
sns.displot(x='tip', data = tips, kind = 'kde')
sns.displot(x='tip', data = tips, kind = 'ecdf')
5.박스플롯
관련용어
- 백분위 수 : 데이터를 백등분 한 것
- 사분위 수 : 데이터를 4등분 한 것
- 제 1사분위 수 (Q1) : 전체 데이터 중 하위 25%에 해당하는 값
- 제 2사분위 수 (Q2) : 전체 데이터 중 하위(상위) 50%에 해당하는 값 = 중간값 (median)
- 제 3사분위 수 (Q3) : 전체 데이터 중 하위 75% (상위 25%)에 해당하는 값
- 제 4사분위 수 (Q4) : 전체 데이터 중 하위 100% (가장 상위)에 해당하는 값
- IQR (사분위 범위) : Q3 - Q1 (데이터의 중간 50%)
- 1.전체 데이터에서 각 사분위수를 계산한다.(Q1,Q2,Q3,Q4)
- 2.그래프에서 제1 사분위와 제3 사분위를 밑변으로 하는 직사각형을 그리고, 제 2사분위에 해당하는 위치(중앙값)에 선분을 긋는다.
- 3.사분위수 범위(IQR = Q3-Q1)을 계산한다.
- 4.Q3+1.5IQR보다 크거나, Q1-1.5IQR의 위치에 max와 min을 표시하고 그보다 바깥쪽의 데이터는 이상치로 간주한다.
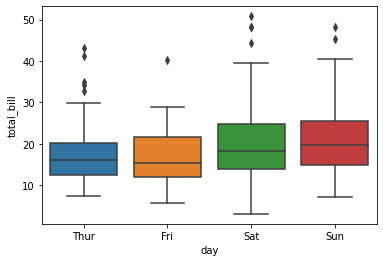
sns.boxplot(x = "day", y = "total_bill", data = tips)
plt.show()
6. Heatmap
- 색깔의 강도에 따라 다른 크기(강도)의 데이터를 표현
1) 상관관계 그래프
- corr() 상관관계보기
- corr() : 변수간 상관계수 표현
- 수치형 데이터만 사용
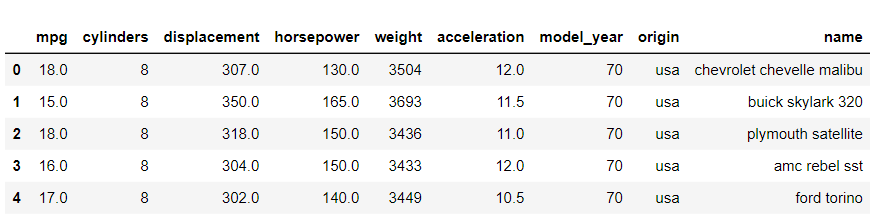
- mpg: 자동차 연비와 관련된 데이터 세트
mpg = sns.load_dataset("mpg")
mpg.shape
mpg.head()
- select_dtypes (include = np.number) - 수치형 변수만 추출 (오류가 날수 있으니 숫자형 데이터만 사용)
num_mpg = mpg.select_dtypes(include = np.number)
num_mpg.shape # 398 행, 7개 열
num_mpg.head() #origin, name이 빠진것을 알 수 있음!
히트맵 보기 좋게 만들기
- cmap: 히트맵의 색을 설정 (plt.cm.RdBu)
- annotation: 값을 주석으로 넣기 (True)
그래프꾸미기
- suplot별 title 표시
- ax.set_title("이름")
- 전체 제목
- fig.suptitle ('Four Plot')
#그래프 꾸미기
fig, ax = plt.subplots(nrows = 1, ncols = 2, figsize=(16, 5))
# 큰제목 넣기
fig.suptitle("heatmap", fontsize=16)
# 기본 그래프 [Basic Correlation Heatmap]
sns.heatmap(num_mpg_corr, cmap="BrBG" , ax=ax[0], vmax=1, vmin=-1)
#subplot의 제목 넣기
ax[0].set_title("heatmap without annot")
# 상관관계 수치 그래프 [Correlation Heatmap with Number]
sns.heatmap(num_mpg_corr, annot=True, cmap="BrBG", ax=ax[1], vmax=1, vmin=-1) # annot=True --> 상관관계 수치 표시
#subplot의 제목 넣기
ax[1].set_title("heatmap with annot")
fig.tight_layout() # 사용하면 플롯간 여백을 조정해준다.
plt.show()
- 변수간 상관관계를 직관적으로 이해할 수 있음Target 변수인 mpg를 대상으로 볼때
- Clylinders, displacement, horsepower, weight 는 강한 음의 상관관계를 가진다!
pairplot
- pairplot은 그리도(grid) 형태로 각 집합의 조합에 대해 히스토그램과 분포도를 그립니다.
- 또한, 숫자형 column에 대해서만 그려줍니다.
sns.pairplot(mpg)
plt.show()