25년 11월 21일 기준으로 되어있는 빅데이터 분석기사 실기 체험 문제 유형 2번 풀이 드립니다.


# 출력을 원하실 경우 print() 함수 활용
# 예시) print(df.head())
# getcwd(), chdir() 등 작업 폴더 설정 불필요
# 파일 경로 상 내부 드라이브 경로(C: 등) 접근 불가
import pandas as pd
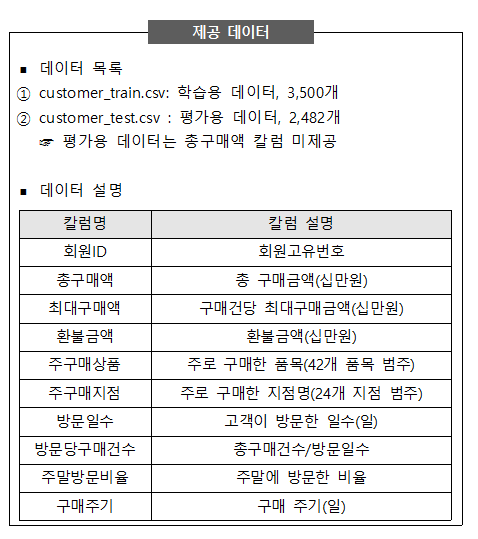
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
#print(test)
#회귀 모델
# 사용자 코딩
train1 = train.copy()
test1 = test.copy()
#print(test1)
#결측치 제거
train1['환불금액'] = train1['환불금액'].fillna(train1['환불금액'].mode()[0])
test1['환불금액'] = test1['환불금액'].fillna(test1['환불금액'].mode()[0])
#라벨 인코더
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
train1['주구매상품'] = le.fit_transform(train1['주구매상품'])
train1['주구매지점'] = le.fit_transform(train1['주구매지점'])
test1['주구매상품'] = le.fit_transform(test1['주구매상품'])
test1['주구매지점'] = le.fit_transform(test1['주구매지점'])
# print(train1.info())
# print(test1.info())
#자료 나누기
from sklearn.model_selection import train_test_split
x = train1.drop(columns = ['총구매액'])
y = train1['총구매액']
x_train, x_val, y_train, y_val = train_test_split(x, y, test_size = 0.2, random_state = 2024)
#모델링
from sklearn.ensemble import RandomForestRegressor
rfr = RandomForestRegressor(n_estimators = 120, max_depth=15, random_state = 2025)
rfr.fit(x_train, y_train)
# print(help(RandomForestRegressor))
#예측
pred1 = rfr.predict(x_val)
# print(pred1)
#성능 평가
from sklearn.metrics import mean_squared_error
import numpy as np
mse = mean_squared_error(y_val, pred1)
rmse = np.sqrt(mse)
# print(rmse)
#예측
test_x_data = test1
pred2 = rfr.predict(test_x_data)
print(pred2)
#결과 제출 및 확인
pd.DataFrame({'pred':pred2}).to_csv('result.csv', index=False)
result = pd.read_csv("result.csv")
# print(result.head())
# print(result.shape)
# 답안 제출 참고
# 아래 코드는 예시이며 변수명 등 개인별로 변경하여 활용
# pd.DataFrame변수.to_csv("result.csv", index=False)'Python > 빅데이터분석기사 실기' 카테고리의 다른 글
| 빅분기 실기 11회 대비 정리(작업형 1유형) (0) | 2025.11.26 |
|---|---|
| (2015.11.16) 빅데이터분석기사 실기 체험 문제 (0) | 2025.11.16 |
| 빅분기 실기 유형 3 정리 (가설 검정 및 통계 분석) (0) | 2025.11.13 |
| 빅분기 실기 유형 1 기출문제 코드 (set_option, unique) (0) | 2025.11.11 |
| 빅분기 실기 유형 1 기출문제 코드 (corr) (0) | 2025.11.09 |